Loan Default Prediction
Using PySpark to Predict Loan Default
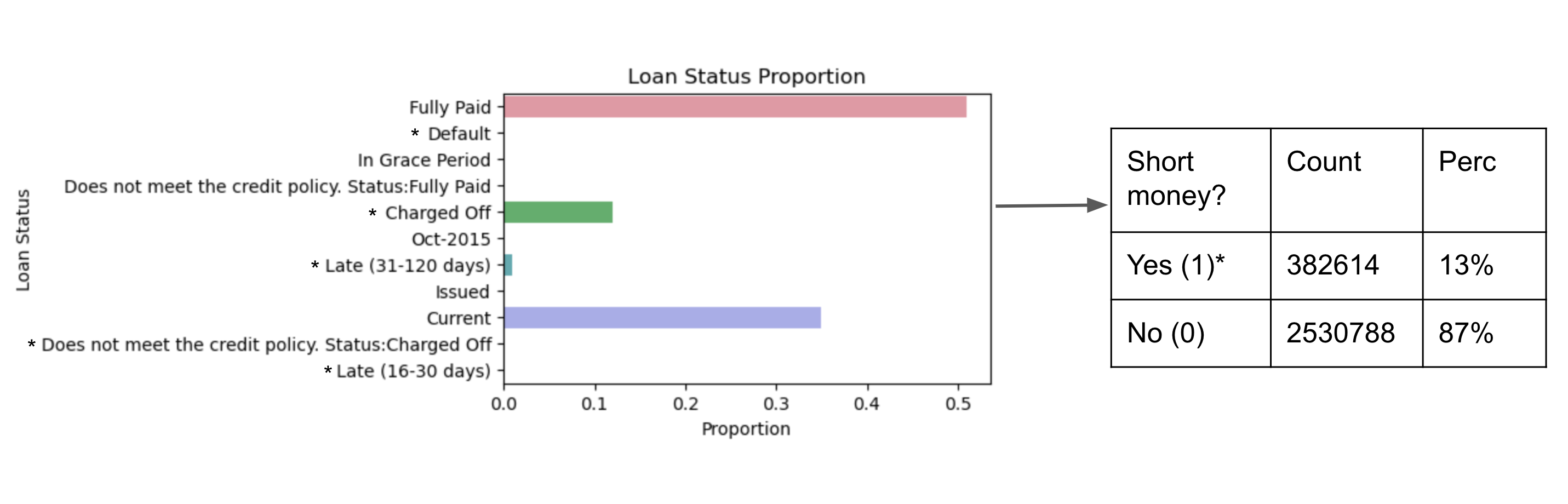
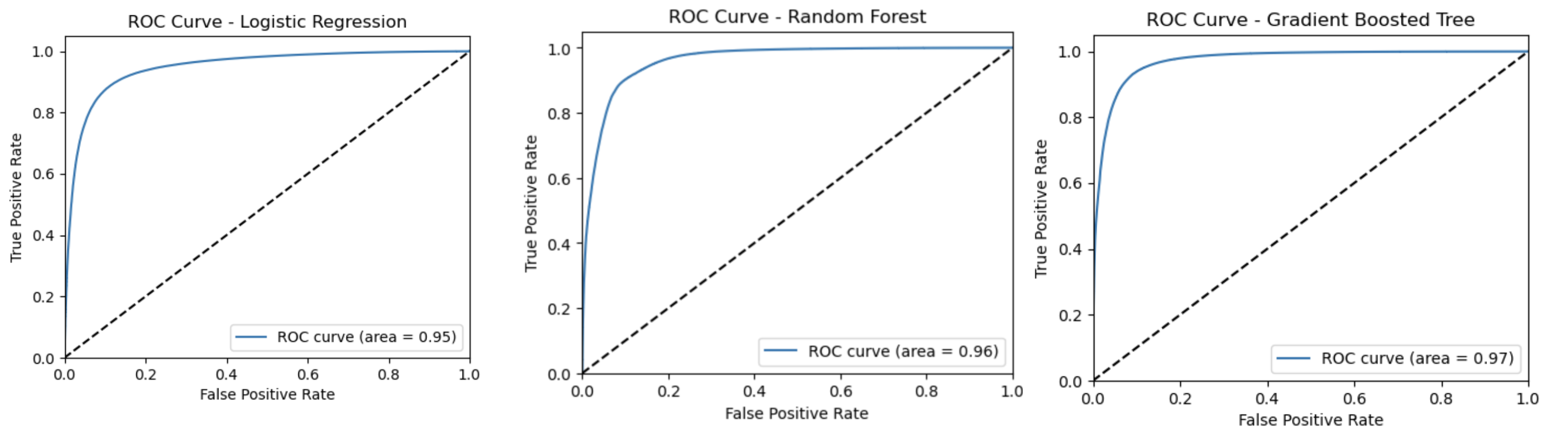
This was a group final project undertaken for Big Data Systems as part of the UVA MSDS program. Kristy Bell, Celine Feng, and I used Lending Club loan data spanning from 2007 to 2013 to predict loan risk. Given the size of the dataset (~3M loans), we worked exclusively in PySpark to explore how well we could predict whether or not a loan would lose money (be late or eventually charged off). We implemented a range of models that topped > 90% accuracy including a logistic regression, a gradient boosted tree, a random forest, and a linear support vector machine. After hyperparameter tuning, we found our tree-based methods to be the most promising.